The goal of this project is to build a movie recommendation system for Netflix users using historical ratings data. The system leverages two key techniques:
Collaborative Filtering (using Singular Value Decomposition - SVD) to predict user ratings for movies they haven't seen.
Content-Based Filtering (using Pearson Correlation) to recommend movies similar to those a user has already rated highly.
The system aims to improve user engagement by providing personalized movie suggestions, helping users discover content they are likely to enjoy.
Problem Description
Netflix, like many streaming platforms, faces the challenge of delivering personalized recommendations to its vast user base. With millions of movies and shows available, users often struggle to find content that aligns with their preferences. This project addresses this challenge by building a recommendation system that predicts user preferences based on historical ratings and suggests movies that are most likely to match their tastes.
Dataset
The dataset used in this project is the Netflix Prize Dataset, which is publicly available on Kaggle. This dataset contains over 100 million ratings from more than 480,000 users for 17,770 movies. The data spans from 1999 to 2005 and includes:
User IDs: Unique identifiers for each user.
Movie IDs: Unique identifiers for each movie.
Ratings: Ratings on a scale of 1 to 5.
Timestamps: The date and time of each rating.
The dataset is divided into multiple files, with the primary file used in this project being combined_data_1.txt.
Key Features
Collaborative Filtering (SVD):
Predicts ratings for movies a user hasn't seen based on the preferences of similar users.
Uses Singular Value Decomposition (SVD) to identify latent factors in the data.
Evaluated using cross-validation and metrics like RMSE (Root Mean Squared Error) and MAE (Mean Absolute Error).
Content-Based Filtering (Pearson Correlation):
Recommends movies similar to those a user has rated highly.
Uses Pearson Correlation to measure similarity between movies based on user ratings.
Data Preprocessing:
Cleans the dataset by removing low-rated movies and inactive users.
Ensures the dataset contains only high-quality data for accurate recommendations.
Personalized Recommendations:
Provides a list of top 10 recommended movies for a specific user or based on a target movie.
Technologies and Tools
Programming Language: Python
Libraries:
Pandas, NumPy, Matplotlib, Seaborn (for data manipulation and visualization).
Surprise (for collaborative filtering and SVD implementation).
Scipy (for Pearson Correlation).
Data Storage: CSV files for movie titles and ratings.
Model Persistence: Pickle for saving and loading the trained SVD model.
Methodology
1. Data Loading and Inspection
The dataset contains over 24 million rows of user ratings for movies. The initial steps involve:
Loading the dataset.
Inspecting the data types and structure.
Visualizing the distribution of ratings to understand user behavior.
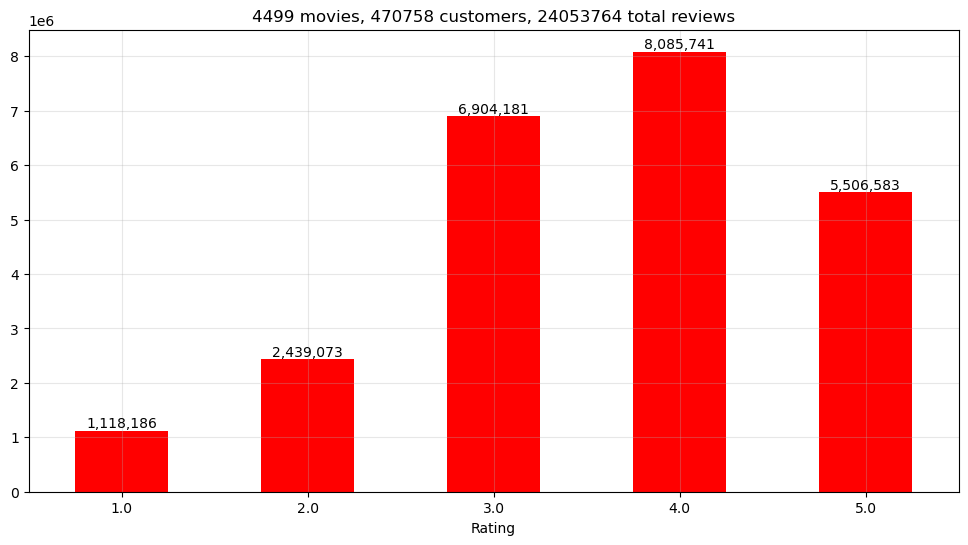
Figure 1: Bar chart showing the distribution of ratings (1-star to 5-star).
Key Insights:
Highest Reviews at 4-star: The bar for the 4-star rating has the highest number of reviews, with over 8 million reviews. This suggests that a large portion of the movies in the dataset have been well-received by customers, earning high ratings.
Substantial 5-star Reviews: The 5-star rating bar shows the second-highest number of reviews, with over 5.5 million. This indicates that a significant number of movies have received excellent customer feedback.
Fewer Low-rated Movies: The 1-star and 2-star rating bars have the lowest number of reviews, around 1.1 million and 2.4 million, respectively. This implies that the dataset contains fewer movies that have been poorly rated by customers.
Large Customer Base: With 475,257 customers providing a total of 24,053,764 reviews, this dataset represents a substantial user base engaging with the movies.
2. Data Cleaning
To ensure the dataset is suitable for modeling, the following cleaning steps are performed:
Extract Movie IDs: Separate movie IDs from the combined dataset.
Remove Null Values: Filter out rows with missing ratings.
Remove Low-Rated Movies and Inactive Users: Drop movies and users with fewer ratings than a specified threshold (60th percentile).
3. Collaborative Filtering with SVD
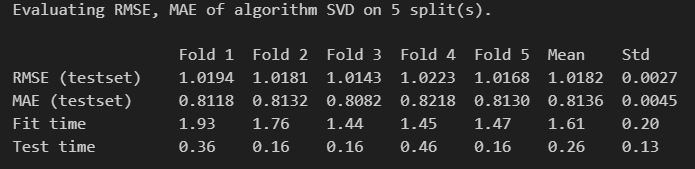
The SVD model is initialized and evaluated using 5-fold cross-validation. The model achieves an RMSE of 1.018 and MAE of 0.814, indicating good predictive accuracy. After validation, the model is trained on the full dataset to make personalized predictions.
Figure 2: Cross-validation results showing RMSE and MAE for each fold.
4. Content-Based Filtering with Pearson Correlation
A pivot table is created to represent user ratings for each movie. Pearson Correlation is used to calculate similarity between movies based on user ratings. A function is implemented to recommend the top 10 movies similar to a given movie.
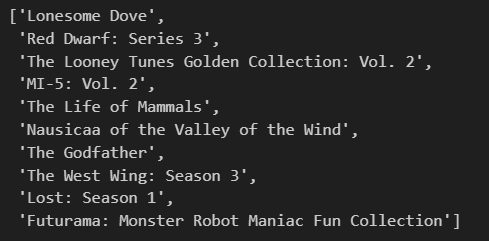
Figure 3: Top 10 movies similar to 'X-Men United'.
5. Model Persistence
The trained SVD model is saved using Pickle for future use. The model can be loaded to make predictions for new users or movies.
Results and Insights
The system successfully predicts user ratings and recommends movies based on both collaborative and content-based filtering. Collaborative Filtering excels at identifying latent patterns in user preferences, while Content-Based Filtering provides direct recommendations based on movie similarity. The combination of these techniques ensures a diverse yet relevant set of recommendations.
Figure 4: Top 10 movies recommended for User 712664.
Conclusion
This project demonstrates the power of combining collaborative filtering and content-based filtering to build a robust recommendation system. By leveraging historical ratings data from the Netflix Prize Dataset on Kaggle, the system provides personalized movie suggestions that enhance user engagement and satisfaction. The use of SVD and Pearson Correlation ensures that the recommendations are both accurate and relevant, making it a valuable tool for platforms like Netflix.